在 K8s 上,可經由容器或 POD 請求或使用的計算資源有記憶體和 CPU。相互比較的話前者為不可壓縮資源,做一些伸縮操作可能會有問題,而後者事可壓縮資源,可以做伸縮的操作。
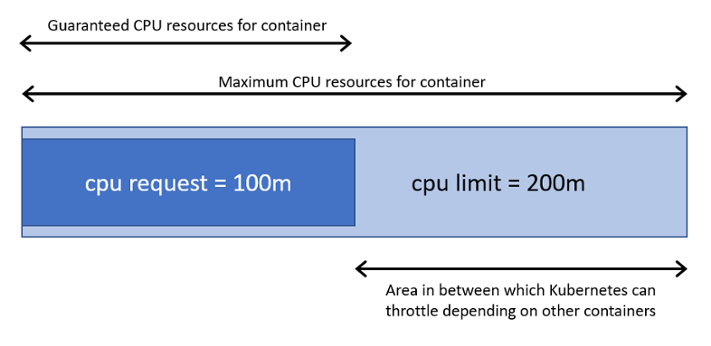
資源隔離目前是屬於容器級別,而資源藉由 requests 定義請求的可最小可用值,另一個 limits 用於限制資源最大可用值,如下圖所示。在 K8s 上,一個單位的 CPU 相當於虛擬機上的一顆 vCPU 或實體機上的一個 Hyperthread(一個邏輯 CPU),一個核心相當於 1000 個微核心所以200m 相當於 0.2 個核心。記憶體以 Ei、Pi、Ti、Ki 等單位作為計算。
 from “https://jaxenter.com/manage-container-resource-kubernetes-141977.html"
from “https://jaxenter.com/manage-container-resource-kubernetes-141977.html"
Example
requests
apiVersion: v1
kind: Pod
metadata:
name: stress-pod
labels:
app: test
spec:
containers:
- name: stress
image: ikubernetes/stress-ng
command: ["/usr/bin/stress-ng", "-c 1", "-m 1", "--metrics-brief"]
resources:
requests:
memory: "128Mi"
cpu: "200m"
配置清單上,POD 要求為容器要有 128Mi 記憶體和 5 分之 1 的 CPU 核心的最小資源。使用 -m 1 進行記憶體的壓測,滿載時盡可能占用 CPU 資源,同時間 -c 1 是對 CPU 進行壓測。
當上面的資源清單建立後,使用 exec 對容器執行 top 進行觀察。
$ kubectl exec stress-pod -- top
Mem: 2067432K used, 1976380K free, 3496K shrd, 102096K buff, 962844K cached
CPU: 99% usr 0% sys 0% nic 0% idle 0% io 0% irq 0% sirq
Load average: 1.04 0.29 0.12 3/509 13
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
8 7 root R 262m 7% 0 48% {stress-ng-vm} /usr/bin/stress-ng
6 1 root R 6900 0% 1 48% {stress-ng-cpu} /usr/bin/stress-ng
1 0 root S 6256 0% 0 0% /usr/bin/stress-ng -c 1 -m 1 --met
7 1 root S 6256 0% 0 0% {stress-ng-vm} /usr/bin/stress-ng
9 0 root R 1516 0% 0 0% top
測試用的行程 CPU 占用率為 48%,stress-ng-vm 的記憶體占 262m(VSZ),其兩項資源都超出請求量,stress-ng 會在可用的範圍內盡量的占用相關的資源。內存為不可壓縮資源,因此 POD 在記憶體資源過載時可能會因 OOM 而被終止,而 CPU 則是會將多占用資源壓縮。因此,在 K8s 上運行關鍵應用程式相關的 POD 時需使用requests 定義最小可用資源。
limits
limits 定義容器資源最大可用。定義此屬性可避免應用程式出現 Bug 導致資源長期被占用。下面的記憶體資源只要超出 limits 定義資源將被 OOM 終止。
apiVersion: v1
kind: Pod
metadata:
name: memleak-pod
labels:
app: mem
spec:
containers:
- name: simmemleak
image: saadali/simmemleak
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "64Mi"
cpu: "1"
$ kubectl get pod -o wide -w -l app=mem
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
memleak-pod 0/1 OOMKilled 1 22s 10.4.2.11 gke-cluster-1-default-pool-7dc8b11b-r7rg <none> <none>
memleak-pod 0/1 CrashLoopBackOff 1 25s 10.4.2.11 gke-cluster-1-default-pool-7dc8b11b-r7rg <none> <none>
memleak-pod 1/1 Running 2 28s 10.4.2.11 gke-cluster-1-default-pool-7dc8b11b-r7rg <none> <none>
memleak-pod 0/1 OOMKilled 2 29s 10.4.2.11 gke-cluster-1-default-pool-7dc8b11b-r7rg <none> <none>
與 requests 不同的是,limits 不會影響 POD 的調度結果,因此 limits 資源定義可大於節點所擁有的資源,當然過載使用還是會有容器會被 OOM 終止。
POD 的 QoS
當我們設置上一章節所說的屬性,在資源吃緊的情況下,應該要用什麼方式進行先後順序的終止 POD ? K8s 無法自己做出決策,需借助 POD 的優先級別。依照 requests 和 limits 屬性,K8s 將 POD 歸類到三種 QoS 類別下
- Guaranteed
- 每個容器都為
CPU資源設置了具有相同值的requests和limites屬性,以及每個容器都為記憶體資源設置了具有相同值的requests和limits屬性的POD資源會自動歸屬此類,而這類的POD資源具有最高優先權
- 每個容器都為
- Burstable
- 至少有一個容器設置了
CPU或記憶體的requests屬性,但不滿足Guaranteed類別要求的POD資源自動歸屬此類,具有中等優先級別
- 至少有一個容器設置了
- BestEffort
- 沒有為任何容器設置
requests或limits屬性的POD資源自對歸屬此類,優先級別最低
- 沒有為任何容器設置
每個運行的容器都有 OOM 得分,得分越高越會被優先終止。OOM 得分主要根據兩個維度進行計算,由 QoS 類別繼承而來的默認值和容器的可用記憶體資源比例。同等類別的 POD 資源的默認值相同,下面的程式碼從 pkg/kubelet/qos/policy.go 取得,它們定義的是各種類別的 POD 資源 OOM 調節(Adjust)值,即默認值。
在同一等級的優先級別下的 POD 資源在 OOM 時,與自己的 requests 相比,其記憶體占用比例最大的 POD 將被先終止。
const (
PodInfraOOMAdj int = -998
KubeletOOMScoreAdj int = -999
DockerOOMScoreAdj int = -999
KubeProxyOOMScoreAdj int = -999
guaranteedOOMScoreAdj int = -998
besteffortOOMScoreAdj int = 1000
)